DX12和DX11相比有了很多的变化,最核心的便是拉近了开发者和硬件的距离,让开发者能够更接近底层。对于硬件的控制DX12更加直接,更加高效,也增加了更多了可能性(多线程渲染);但与此同时与DX11相比开发者的额外工作量也增加了不少。下面是个人学习笔记的一些整理,希望和大家分享。
基础流程介绍
基础流程的学习主要参考了微软官方DX12编程指南中,创建基础的DX12组件(Creating a basic Direct3D 12 component))这一章节。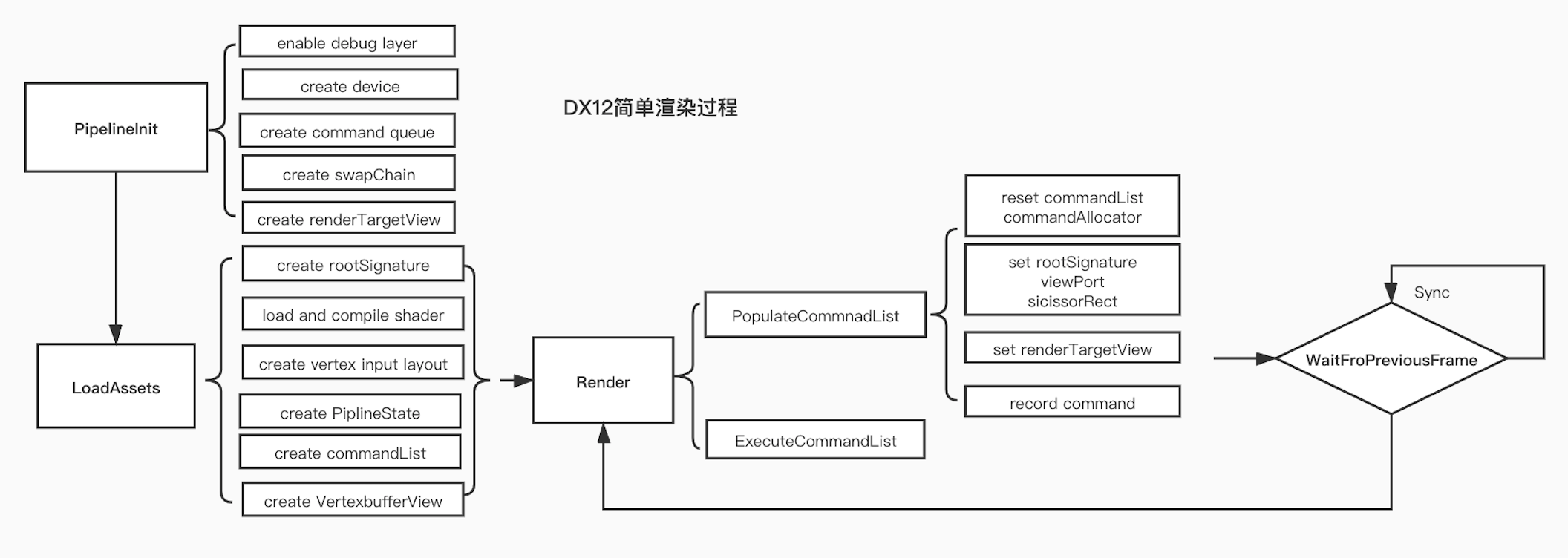
可以看到DX12是通过commandList将渲染指令提交给GPU的,此时cpu和gpu是异步执行的,而他们之前的同步是通过fence实现的。 这也是DX12实现多线程渲染的核心,下面我们看一下WaitFirPreviousFrame这个方法的内容。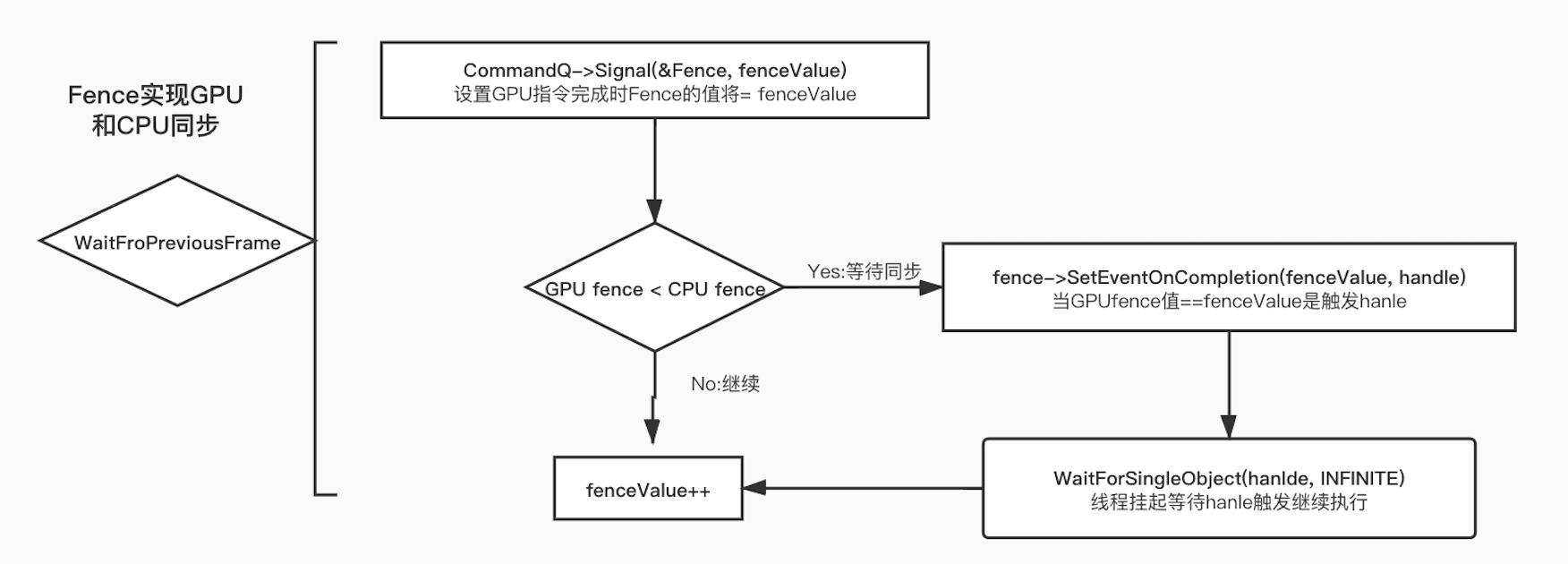
WaitForSingleObject方法会将当前线程挂起,当GPU功能完成时,触发handle信号改变,cpu继续执行。
资源描述
Descriptor
顾名思义是一种描述。是什么的描述呢?各种用于渲染的资源(贴图/模型/参数…),描述对象是谁呢?GPU。
descriptor handle(GPU/CPU),这是一个让我比较疑惑的东西。目前我是这样理解的:同一个descriptor当你需要在CPU使用时则使用CPU handle,当需要在GPU使用时则使用GPU handle。
以下是所有descriptor类型:
Index Buffer View
Vertex Buffer View
Shader Resource View
Constant Buffer View
Sampler
Unordered Access View
Stream output View
Render Target View
Depth Stencil View
Descriptor Heap
多个同类型的descriptor的集合。这里所说发类型主要分为两个类型Shader Visible和No Shader Visible。
Shader Visible主要包括:Shader Resource View/Constant Buffer View/Unorder Access View,指的是可以通过descriptorTable传入shader中使用的资源类型,如下图所示(注:Shader Visible类型的Heap也可以通过设置属性变成No Shader Visible)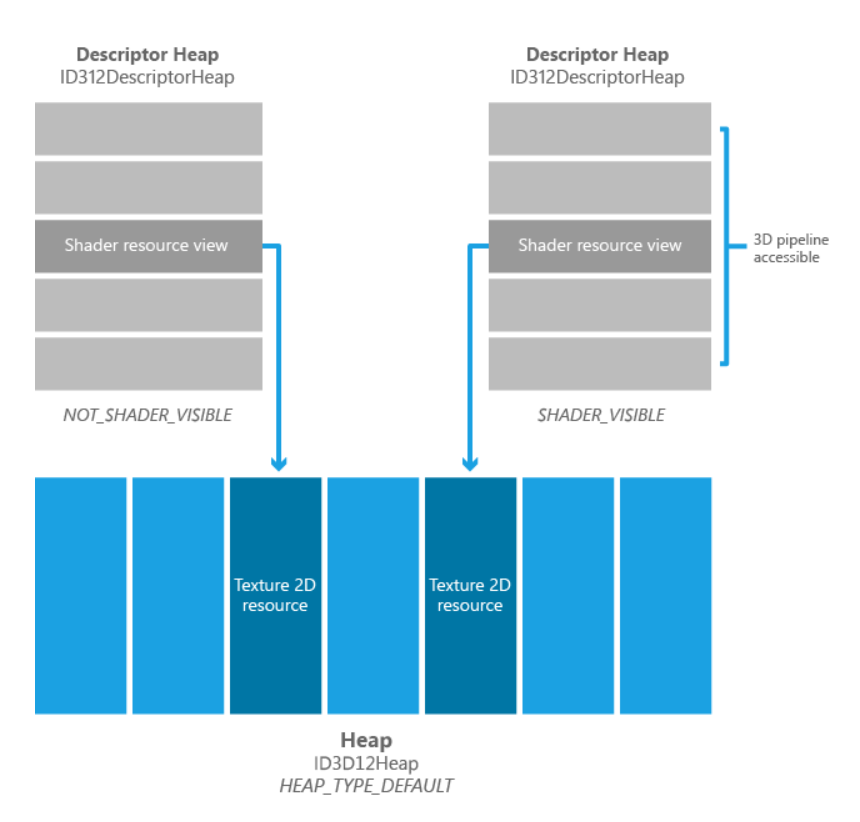
No Shader Visible主要包括Render Target View/Depth Stencil View/Stream Output View,以上类型直接通过参数传递给ComandList使用。
我们发现Index Buffer View和Vertex Buffer View没有包含在上述两种类型中,他们是通过特定API传递的。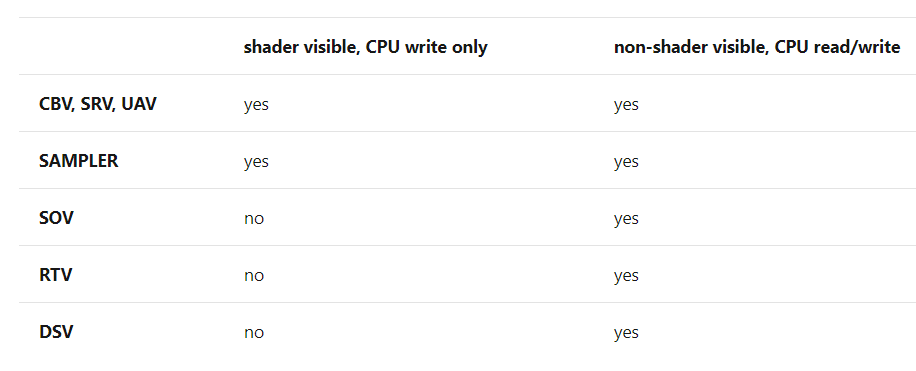
Descriptor Table
用于存放多个的Descriptor(这里指的是shader-visible类型的,cbv/srv/uav/sampler) ,然后通过rootSignature在同步,shader就可以使用以上的descriptor中的资源.
它并不是descriptor实际内存的集合, 而是给出对应Descriptor heap上的集合描述参数。引用官方说明来解释这个一点:
Since memory allocation is a property of a creating a descriptor heap, defining a descriptor table out of one is guaranteed to be as cheap as identifying a region in the heap to the hardware.
RootSignature
它是一份通过commandList提供给shader使用的资源清单;这份清单有3种类型的参数:
常量(inlined)
descriptor(inlined)
descriptor table(和descriptor heap关联)
下图则是官方说明的一份清单:
资源绑定流程梳理
虽然上一篇有一个简单的流程图,但主要的目的是为了理解fence在dx12里的运用。接着本节并加入运用rootSignature绑定shader可见资源相关内容。为了深入理解之前总结的descriptor以及descriptor heap等概念,我们继续基于本节内容梳理一个资源绑定的流程。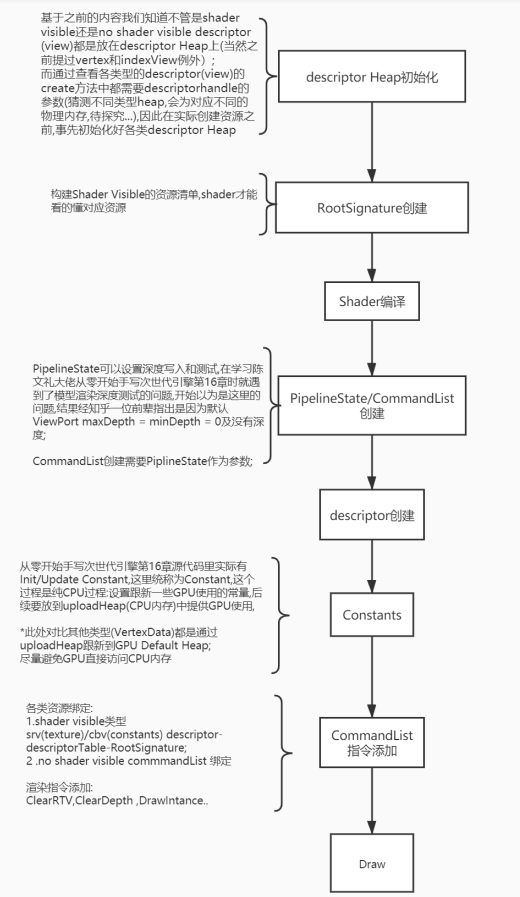
上述流程主要参考了微软官方资源绑定流程和陈文礼大佬的从零开始手写次世代引擎系列第十六章。
遇到的问题归纳
接下来对descriptor创建过程中遇到的一些问题和一些细节探究做一个简单的归纳。
最初我脑海里会有这样的疑问:dx12如何把CPU内存资源放到GPU内存, GPU内存需要什么申请,放在哪里合适? 通过阅读descriptor创建部分的代码, 以及一些相关资料的查阅和分析后,以上疑问得到了部分答案,也帮助我更好的理解的dx12资源绑定过程。
通过调用CreateCommittedResource方法可以创建一种叫Heap的资源,我把这种资源理解为实际物理内存。在从零手写次世代引擎16源代码中出现的两种类型的Heap资源, 下面就是这两种类型的官方介绍:
- D3D12_HEAP_TYPE_DEFAULT (GPU内存)
This heap type experiences the most bandwidth for the GPU, but cannot provide CPU access.
The GPU can read and write to the memory from this pool, and resource transition barriers may be changed.
The majority of heaps and resources are expected to be located here, and are typically populated through resources in upload. - D3D12_HEAP_TYPE_UPLOAD(CPU/GPU共享内存(个人理解),方便CPU写入/GPU读取的内存)
Pecifies a heap used for uploading.
This heap type has CPU access optimized for uploading to the GPU, but does not experience the maximum amount of bandwidth for the GPU.
This heap type is best for CPU-write-once, GPU-read-once data; but GPU-read-once is stricter than necessary.
GPU-read-once-or-from-cache is an acceptable use-case for the data; but such usages are hard to judge due to differing GPU cache designs and sizes.
VertexData的descriptor的创建过程: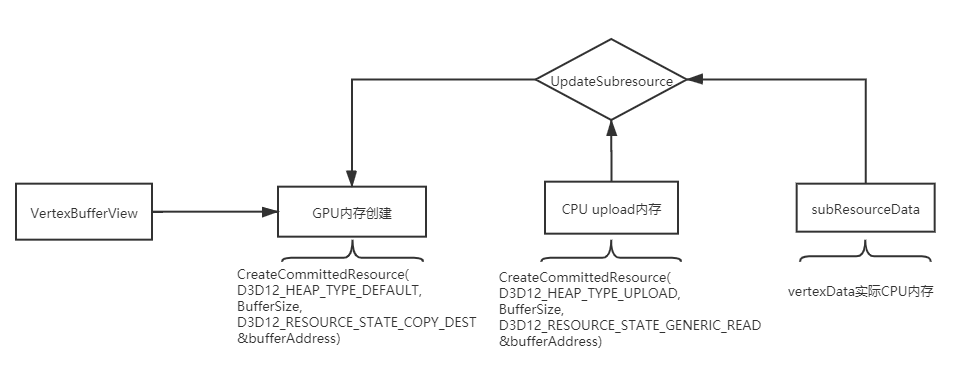
关于D3D_SUBRESOURCE_DESC有两个属性RowPitch和SlicePitch的使用一直不太理解。是因为从零手写次世代引擎16源代码在定义TextureData和indexData时:
indexData.RowPitch == SlicePitch == Stride(结构体位数)
textureData.RowPitch = width * Stride
textureData.SlicePitch = height * RowPitch(total Size)
为了了解一下原因,就进一步进入了UpdateSubresource方法内,查看RowPich和SlicePitch是如何使用的。
回到上面的流程图我们发现UpdateSubresource做了两件事情 1:subResourceData->uploadHeap 2:uploadHeap->gpu,其中第二步是通过CommandList提供的CopyBufferRegion/CopyTextureRegion方法实现,目前并不知道GPU层面实现细节,而第一步则是cpu内存copy的操作,能看到源代码,那就看看RowPitch和SlicePitch在内存copy(subResourceData->uploadHeap)过程到底是如何使用的。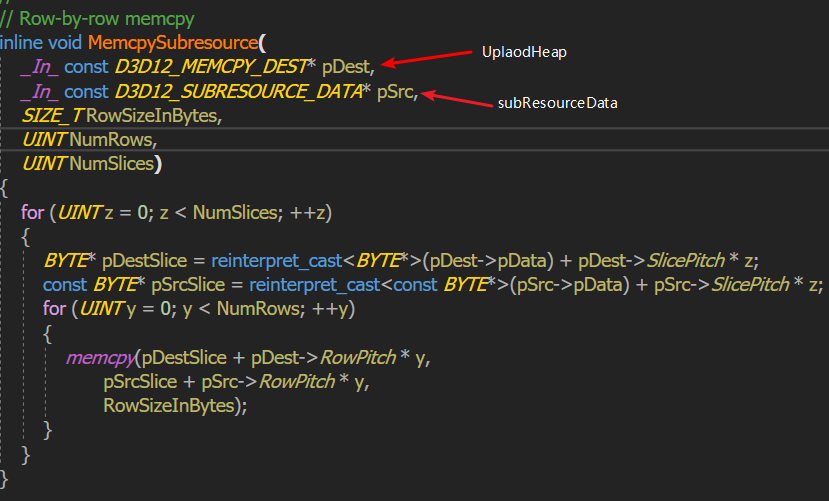
D3D12_MEMCPY_DEST.RowPitch = D3D_SUBRESOURCE_FOOTPRINT.RowPitch
D3D12_MEMCPY_DEST.SlicePitch = D3D_SUBRESOURCE_FOOTPRINT.RowPitch * RowNum (总大小)
可以看到pSrc的RowPitch和SlicePitch需要和pDest也就是uploadHeap的RowPitch和SlicePitch对应(除非NumSlices(depth) = 1, NumRows = 1 正好对应了VertexData和IndexData的情况, 他们的数据是一维排列的, 因此只要数据总长(RowSizeInBytes)正确就能保证正确copy).
uploadHeap的RowPitch和SlicePitch的值是如何得到的呢?下面就需要介绍GetCopyableFootprints方法,该方法则会告诉你与D3D_RESOURCE_DESC对应的资源在UploadHeap中是如何排列的。它会计算记得出4个参数:pLayouts, pNumRows, pRowSizeInBytes,pTotalBytes.
通过这几个参数我们就能得知uploadHeap的排列方式
其中pLayouts的结构如下: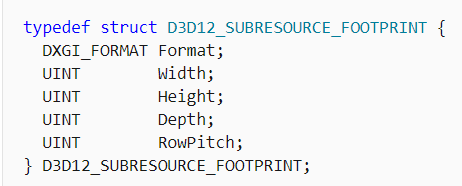
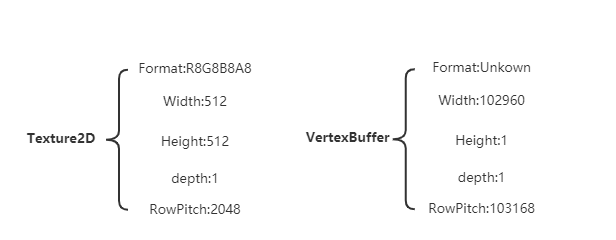
查看不同类型数据的layout可以发现, Texture2D是2维的,而buffer则是一维的。对于一维的buffer而言width自然是数据总长度(format未定义时,宽高的单位是byte), RowPicth为什么不等于Width呢, 查看官方说明是因为对齐方式是256(103168 = (102960 / 256 + 1) * 256)。
再看Texture2D,宽带为512,formant为4bytes所以RowPich = 512 * 4 (正好是256的整数倍),其中depth应该是相对mipLevels而言(ps:可以看到就算mipmap比原图小, 但内存占用却是一样),此如何设置subResource的RowPitch和SlicePitch暂时可以有个答案了。
最后还有一个比较重要的方法就是ResourceBarrier。字面意思就是资源屏障,这个屏障是加的GPU的,主要目的是为了保护一块正在写入的资源内存,防止GPU对其执行其他的行为。这里有一篇对这个概念讲的比较详细的文章推荐给大家A Look Inside D3D12 Resouce State Barriers。
以上就是个人学习笔记的总结和归纳,比较浅显。而且都是查阅资料加上个人理解,如果有不对的地方还希望大家能够指出,感谢!。